


GBase新聞
GBASE金融應(yīng)用指南2 | GBase 8a MPP Cluster 邏輯架構(gòu)
為幫助金融機構(gòu)做好分布式分析型數(shù)據(jù)庫產(chǎn)品的選型,推廣在金融行業(yè)部署應(yīng)用分布式分析型數(shù)據(jù)庫的成功經(jīng)驗,GBASE南大通用在北京金融科技產(chǎn)業(yè)聯(lián)盟的指導(dǎo)下編寫《南大通用GBase 8a金融應(yīng)用指南》。《指南》深入介紹了分布式分析型數(shù)據(jù)庫從選型規(guī)劃、開發(fā)設(shè)計規(guī)范、數(shù)據(jù)安全高可用,直至運維優(yōu)化的部署全過程,并介紹了GBase 8a MPP Cluster在國家政策性銀行和國有大行的代表性部署案例。
GBASE南大通用將陸續(xù)推出系列文章,分享解讀《指南》內(nèi)容,希望能夠?qū)V大金融用戶的數(shù)據(jù)庫選型提供借鑒幫助,助力科技金融的高效實施和高質(zhì)量發(fā)展。
本篇是系列文章的第2期,在上一期介紹分布式分析型數(shù)據(jù)庫的特點分類,及金融行業(yè)應(yīng)用場景的基礎(chǔ)上,進一步介紹金融行業(yè)應(yīng)用的分布式分析型數(shù)據(jù)庫的系統(tǒng)架構(gòu),以及與之對應(yīng)的GBase 8a MPP Cluster產(chǎn)品架構(gòu)。
分布式分析型數(shù)據(jù)庫邏輯架構(gòu)
1、系統(tǒng)架構(gòu)
金融行業(yè)常見的系統(tǒng)架構(gòu)如下圖所示。
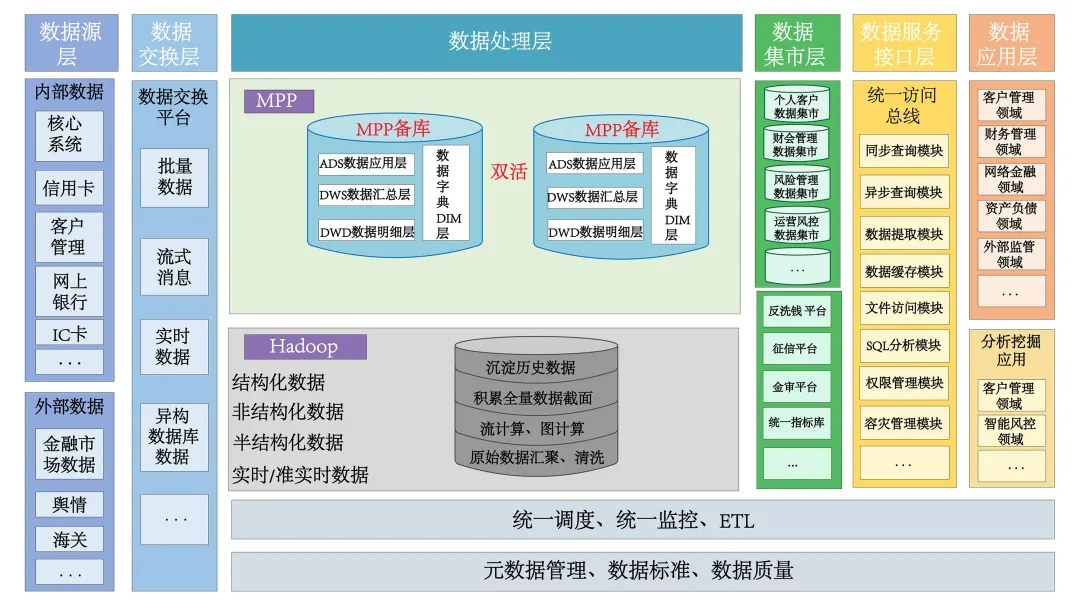
金融行業(yè)常見的系統(tǒng)架構(gòu)
數(shù)據(jù)交換層:用于匯總前端生產(chǎn)系統(tǒng)中的各類數(shù)據(jù),避免跨系統(tǒng)操作影響業(yè)務(wù)運行,保證核心系統(tǒng)中的數(shù)據(jù)的真實性、完整性和唯一性;提供多種數(shù)據(jù)集成方式,滿足批量數(shù)據(jù)、實時數(shù)據(jù)的入庫需求。
數(shù)據(jù)處理層:通常采用Hadoop+MPP的數(shù)據(jù)倉湖架構(gòu)。
– Hadoop通常作為ODS數(shù)據(jù)庫、數(shù)據(jù)湖使用,用于原始數(shù)據(jù)匯聚和存儲、數(shù)據(jù)規(guī)范化處理、積累全量數(shù)據(jù)截面、沉淀歷史數(shù)據(jù)資產(chǎn)、處理非結(jié)構(gòu)化數(shù)據(jù)等。
– MPP通常作為數(shù)據(jù)倉庫,負責(zé)結(jié)構(gòu)化數(shù)據(jù)的高性能統(tǒng)計分析。在MPP中通常按照數(shù)據(jù)庫倉庫模型對業(yè)務(wù)數(shù)據(jù)進行邏輯分層加工處理。分析后的結(jié)果數(shù)據(jù)通過導(dǎo)出、DBLink、虛擬集群跨業(yè)務(wù)訪問等方式提供數(shù)據(jù)給上層服務(wù)使用。
數(shù)據(jù)集市層:通常存儲為特定用戶預(yù)先計算好的數(shù)據(jù),即數(shù)據(jù)處理層的分析結(jié)果提供給數(shù)據(jù)集市,結(jié)合本地數(shù)據(jù)進行二次加工分析,滿足用戶特定主題域的需求,如報表查詢服務(wù)。
數(shù)據(jù)服務(wù)接口層和數(shù)據(jù)應(yīng)用層:對前端業(yè)務(wù)提供數(shù)據(jù)訪問接口和查詢服務(wù)。
GBase 8a MPP Cluster在金融行業(yè)的系統(tǒng)架構(gòu)中主要用于數(shù)據(jù)處理層和數(shù)據(jù)集市層。
2、GBase 8a產(chǎn)品架構(gòu)
GBase 8a MPP Cluster產(chǎn)品架構(gòu)圖如圖所示
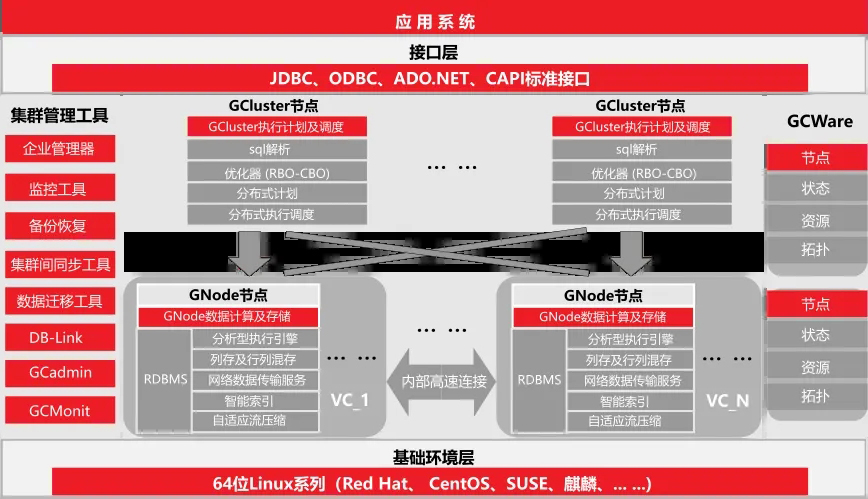
GBase 8a MPP Cluster產(chǎn)品架構(gòu)圖
GBase 8a MPP Cluster采用MPP + Shared Nothing 的分布式聯(lián)邦架構(gòu),包含分布式管理集群GCWare、分布式調(diào)度集群GCluster和分布式存儲計算集群GNode三大核心組件。主要功能特性如下:
? 高性能:列存、行存列、HASH索引
– 采用列存儲、壓縮、智能索引技術(shù);在數(shù)據(jù)倉庫場景下通常采用中度壓縮算法提供1:3到1:5的壓縮比;
– 采用行存列降低select *場景下的I/O量;
– 采用HASH索引、數(shù)據(jù)排序等手段提高等值查詢性能;
– MPP多節(jié)點并行,性能隨集群規(guī)模線性提升;
–支持向量化計算,提高計算速度。
? 跨業(yè)務(wù)集群管理和交互:虛擬集群、DBLink
– 虛擬集群通過統(tǒng)一的管理集群實現(xiàn)對多個計算集群的統(tǒng)一管理、統(tǒng)一訪問入口、統(tǒng)一用戶權(quán)限控制,多個計算集群間資源隔離。支持用戶跨計算集群進行數(shù)據(jù)的訪問與計算。在多個業(yè)務(wù)系統(tǒng)間數(shù)據(jù)關(guān)聯(lián)性較高時,可采用虛擬集群方式進行數(shù)據(jù)管理;
– 提供DBLink支持不同集群間的DBlink訪問,實現(xiàn)跨集群的數(shù)據(jù)流轉(zhuǎn),實現(xiàn)對遠程數(shù)據(jù)庫的查詢以及遠程數(shù)據(jù)與本地數(shù)據(jù)的關(guān)聯(lián)運算等。
? 高可用能力:聯(lián)邦架構(gòu)無單點、備份恢復(fù)、雙活集群、在線節(jié)點替換
– 聯(lián)邦架構(gòu)無單點:所有組件采用Active-Active多活部署,避免了單點性能瓶頸和單點故障;
– 備份恢復(fù):提供實例級、庫級、表級的備份和恢復(fù)功能,支持全量、增量備份和恢復(fù);
– 雙活集群:支持實時雙活、異步雙活方案。通過虛擬集群鏡像技術(shù),支持兩個計算集群間的表級數(shù)據(jù)實時復(fù)制。提供集群間同步工具實現(xiàn)兩個集群間的數(shù)據(jù)異步一致性同步,點對點的基于二進制文件進行增量同步具有較高的同步性能,同時支持異地雙活部署,支持兩地三中心部署;
– 在線節(jié)點替換:具有在線不停服的節(jié)點替換能力,故障節(jié)點替換過程中,支持集群執(zhí)行DQL/DML/DDL操作。
? 高擴展能力:在線擴展
– 集群擴展過程無需停服,擴容期間支持對擴容操作的監(jiān)控、暫停、恢復(fù)、取消。滿足業(yè)務(wù)實時在線要求和降低集群擴容對業(yè)務(wù)的性能影響。
? 數(shù)據(jù)集成能力:高性能批量加載、實時數(shù)據(jù)入庫、hadoop集成
– 高性能批量加載:基于策略的數(shù)據(jù)加載模式,采用副本鏈式轉(zhuǎn)發(fā)、P2P多點傳輸、多加載機并行等方式可提供30TB/小時的加載性能;支持HTTP、FTP/SFTP、HDFS、Kafka、S3等多種數(shù)據(jù)源及網(wǎng)絡(luò)協(xié)議,支持文本、ORC、Parquet、gzip、snnapy、lzo等多種壓縮格式。支持從HDFS加載數(shù)據(jù)和導(dǎo)出數(shù)據(jù)到HDFS,方便與Hadoop集群進行數(shù)據(jù)交互;
–支持外部表,可實現(xiàn)直接讀取HDFS、S3、FTP等數(shù)據(jù)源的開放格式數(shù)據(jù)文件進行直接計算;
– 實時數(shù)據(jù)入庫:內(nèi)置Kafka Consumer組件可以消費Kafka中的實時消息數(shù)據(jù);提供GBaseRTSync工具實現(xiàn)從OLTP數(shù)據(jù)庫到MPP的實時數(shù)據(jù)同步。
? 安全能力:權(quán)限管理、用戶安全、透明存儲加密、脫敏
– 提供完善的用戶認證及權(quán)限管理;
– 數(shù)據(jù)加密存儲在文件系統(tǒng)中,支持表級、列級加密,支持SM4國密算法,滿足數(shù)據(jù)安全要求;
– 提供動態(tài)數(shù)據(jù)脫敏功能,通過權(quán)限控制原始數(shù)據(jù)的可見范圍,簡化了數(shù)據(jù)庫應(yīng)用層的安全設(shè)計和編碼。
? 基于機器學(xué)習(xí)的數(shù)據(jù)挖掘能力
– 提供機器學(xué)習(xí)擴展庫插件,實現(xiàn)機器學(xué)習(xí)算法集成,對用戶數(shù)據(jù)進行深層次的分析和挖掘;
–支持Python、C/C++的UDF/UDAF,可實現(xiàn)算法函數(shù)擴展,滿足用戶自定義數(shù)據(jù)挖掘分析需求。
? 易用能力:可視化監(jiān)控
– 提供可視化的運維管理工具GDOM,支持對GBase 8a MPP Cluster集群的安裝、升級、擴容、節(jié)點替換、服務(wù)啟停等運維管理,支持監(jiān)控單個或多個GBase 8a MPP Cluster集群的運行狀態(tài),資源利用情況、SQL執(zhí)行情況等;提供及時告警、趨勢展示功能。